目录
1. 基础概念
1.1 并发问题的来源
三个基本原则:可见性、原子性、有序性
1.1.1 缓存导致的可见性问题
为了对齐cpu速度与内存速度的差异化,在cpu与内存之间增加了缓存架构,由于预加载cpu处理数据,以此来充分利用 cpu。在单核 cpu 的时候,只有一份缓存,用起来并没有问题,而当多核cpu协同处理问题时,就会出现缓存与实际数据不一致的情况。于是cpu引入了,一致性的协议MESI。
在编程中,一个线程对共享变量的修改,另外一个线程能够立刻看到,我们称为可见性。
1.1.2 线程切换带来的原子性问题
多线程并发处理问题时,时通过轮询时间片的方式来获得并发能力的,而在执行多个cpu指令时,如果发送了线程切换,并且线程间共用公有资源,就会发生第一个线程处理到一半,第二个线程又拿过去处理,这种就是操作间咩有原子性。在一个或者多个操作在 CPU 执行的过程中不被中断的特性称为原子性。
1.1.3 编译优化带来的有序性问题
在编译过程中,会对指令顺序进行优化,这个过程在java中叫指令重排
编译器调整了语句的顺序,但是不影响程序的最终结果,但有时会影响判断,出现异常
1.2 jvm 内存模型中的并发问题
Java 内存模型规范了 JVM 如何提供按需禁用缓存和编译优化的方法。具体来说,这些方法包括 volatile、synchronized 和 final 三个关键字,以及六项 Happens-Before 规则
1.2.1 可见性规则:Happens-Before
关于 volatile
**volatile 的作用在于:**告诉编译器,对这个变量的读写,不能使用 CPU 缓存,必须从内存中读取或者写入
Hanpens-Before : 前面一个操作的结果对后续操作是可见的,其规则如下
1. 程序的顺序性规则
前面的操作 Happens-Before 于后续的任意操作,程序前面对某个变量的修改一定是对后续操作可见的
2. volatile 变量规则
一个 volatile 变量的写操作, Happens-Before 于后续对这个 volatile 变量的读操作
3. 传递性
A Happens-Before B, B Happens-Before C 则 A 必定 Happens-Before C
4. 管程中锁的规则
管程是一种通用的同步原语,在 Java 中指的就是 synchronized,synchronized 是 Java 里对管程的实现。
管程中锁的规则: 这条规则是指对一个锁的解锁 Happens-Before 于后续对这个锁的加锁。
5. 线程 start() 规则
这条是关于线程启动的。它是指主线程 A 启动子线程 B 后,子线程 B 能够看到主线程在启动子线程 B 前的操作。
即 start() 操作 Happens-Before 于被启动的线程中的任意操作
6. 线程 join() 规则
指主线程 A 等待子线程 B 完成(主线程 A 通过调用子线程 B 的 join() 方法实现),当子线程 B 完成后(主线程 A 中 join() 方法返回),主线程能够看到子线程的操作。当然所谓的“看到”,指的是对共享变量的操作
7. 程序中断规则
对线程interrupted()方法的调用先行于被中断线程的代码检测到中断时间的发生。
8. 对象finalize规则
一个对象的初始化完成(构造函数执行结束)先行于发生它的finalize()方法的开始。
1.3 原子性问题:互斥锁
原子性的问题时源自于线程的切换,那么我们可以认为在操作过程中只要保持线程不切换,一路走到底就不会有原子性问题
同一时刻只有一个线程执行称之为互斥
1.3.1 synchronized
Java 编译器会在 synchronized 修饰的方法或代码块前后自动加上加锁 lock() 和解锁 unlock(),这样做的好处就是加锁 lock() 和解锁 unlock() 一定是成对出现的
隐式规则:
-
当修饰静态方法的时候,锁定的是当前类的 Class 对象;
-
当修饰非静态方法的时候,锁定的是当前实例对象 this;
用不同的锁对受保护资源进行精细化管理,能够提升性能。这种锁还有个名字,叫细粒度锁
java
class Account {
// 锁:保护账户余额
private final Object balLock
= new Object();
// 账户余额
private Integer balance;
// 锁:保护账户密码
private final Object pwLock
= new Object();
// 账户密码
private String password;
// 取款
void withdraw(Integer amt) {
synchronized(balLock) {
if (this.balance > amt){
this.balance -= amt;
}
}
}
// 查看余额
Integer getBalance() {
synchronized(balLock) {
return balance;
}
}
// 更改密码
void updatePassword(String pw){
synchronized(pwLock) {
this.password = pw;
}
}
// 查看密码
String getPassword() {
synchronized(pwLock) {
return password;
}
}
// 利用多个对象(转账账号和目标账号)锁定资源
void transfer(Account target, int amt){
// 锁定转出账户
synchronized(this) {
// 锁定转入账户
synchronized(target) {
if (this.balance > amt) {
this.balance -= amt; target.balance += amt;
}
}
}
}
}
1.3.2 死锁
在对锁粒度进行优化(如下代码),容易一组互相竞争资源的线程因互相等待,导致“永久”阻塞的现象这个称为死锁问题
java// 利用多个对象(转账账号和目标账号)锁定资源
void transfer(Account target, int amt){
// 锁定转出账户
synchronized(this) {
// 锁定转入账户
synchronized(target) {
if (this.balance > amt) {
this.balance -= amt; target.balance += amt;
}
}
}
}
死锁的因素(满足所有即会造成死锁)
-
互斥,共享资源 X 和 Y 只能被一个线程占用;
-
占有且等待,线程 T1 已经取得共享资源 X,在等待共享资源 Y 的时候,不释放共享资源 X;
-
不可抢占,其他线程不能强行抢占线程 T1 占有的资源;
-
循环等待,线程 T1 等待线程 T2 占有的资源,线程 T2 等待线程 T1 占有的资源,就是循环等待。
所以,避免死锁的方法就是破坏以上任意一个因素。
1. 破坏占用且等待条件
要破坏这个条件,可以一次性申请所有资源
“同时申请”这个操作是一个临界区,我们也需要一个角色(Java 里面的类)来管理这个临界区,我们就把这个角色定为 Allocator。它有两个重要功能,分别是:同时申请资源 apply() 和同时释放资源 free()。
java
class Allocator {
private List<Object> als =
new ArrayList<>();
// 一次性申请所有资源
synchronized boolean apply(Object from, Object to){
if(als.contains(from) || als.contains(to)){
return false;
} else {
als.add(from);
als.add(to);
}
return true;
}
// 归还资源
synchronized void free(Object from, Object to){
als.remove(from);
als.remove(to);
}
}
class Account {
// actr应该为单例
private Allocator actr;
private int balance;
// 转账
void transfer(Account target, int amt){
// 一次性申请转出账户和转入账户,直到成功
while(!actr.apply(this, target))
;
try{
// 锁定转出账户
synchronized(this){
// 锁定转入账户
synchronized(target){
if (this.balance > amt){
this.balance -= amt;
target.balance += amt;
}
}
}
} finally {
actr.free(this, target)
}
}
}
2. 破坏不可抢占条件
核心是要能够主动释放它占有的资源,这一点 synchronized 是做不到的。java.util.concurrent 这个包下面提供的 Lock 是可以轻松解决这个问题的
3. 破坏循环等待条件
需要对资源进行排序,然后按序申请资源。
1.3.3 等待 - 通知机制
[1.3.2](##### 1. 破坏占用且等待条件) 中使用 apply() 获取锁,在并发冲突量不大时比较好用,当并发冲突变大等待时间变长,就会大量消耗cpu资源(不停循环),这就不合适了。这时候就需要等待 - 通知机制
1.3.3.1 synchronized 实现等待 - 通知机制
synchronized 配合 wait()、notify()、notifyAll() 这三个方法就能轻松实现等待 - 通知机制
synchronized (晋升成重量级锁后)内部实现:
- 请求同步资源
- 资源空闲,进入资源执行代码
- 资源已被占用,调用锁 wait() 方法,等待资源释放
- 资源释放后,调用 notify() 通知 wait() 的线程,告诉它条件曾经满足过
- 继续抢占资源
使用 wait() notifyAll() 修改 apply()
java
class Allocator {
private List<Object> als;
// 一次性申请所有资源
synchronized void apply(Object from, Object to){
// 经典写法
while(als.contains(from) || als.contains(to)){
try{
// wait 会释放所持有的锁
wait();
}catch(Exception e){
}
}
als.add(from);
als.add(to);
}
// 归还资源
synchronized void free(
Object from, Object to){
als.remove(from);
als.remove(to);
notifyAll();
}
}
notify() 是会随机地通知等待队列中的一个线程,而 notifyAll() 会通知等待队列中的所有线程
wait()与sleep()
- 区别:
- wait会释放所有锁而sleep不会释放锁资源.
- wait只能在同步方法和同步块中使用,而sleep任何地方都可以.
- wait无需捕捉异常,而sleep需要.
- 相同:
- 都会让出CPU执行时间,等待再次调度!
wait()方法会释放对象的“锁标志”。当调用某一对象的wait()方法后,会使当前线程暂停执行,并将当前线程放入对象等待池中,直到调用了notify()方法后,将从对象等待池中移出任意一个线程并放入锁标志等待池中,只有锁标志等待池中的线程可以获取锁标志,它们随时准备争夺锁的拥有权。
当调用了某个对象的notifyAll()方法,会将对象等待池中的所有线程都移动到该对象的锁标志等待池。
sleep()方法需要指定等待的时间,它可以让当前正在执行的线程在指定的时间内暂停执行,进入阻塞状态,该方法既可以让其他同优先级或者高优先级的线程得到执行的机会,也可以让低优先级的线程得到执行机会。
但是sleep()方法不会释放“锁标志”,也就是说如果有synchronized同步块,其他线程仍然不能访问共享数据。
1.4 安全性、活跃性、性能问题
1.4.1 安全性问题
这个方法不是线程安全的,这个类不是线程安全的,等等。其中的不安全究竟指的什么呢?
线程安全,本质上是指正确性,含义就是程序按照我们期望的执行
怎么写出线程安全的代码呢,那就是要避免出现原子性问题,一致性问题,有序性问题
一般会出现线程安全问题的只有一种情况:存在共享数据并且该数据会发生变化,通俗地讲就是有多个线程会同时读写同一数据
数据竞争(Data Race): 多线程写一个数据
竞态条件(Race Condition): 指的是程序的执行结果依赖线程执行的顺序。
java// 数据竞争
public class Test {
private long count = 0;
void add10K() {
int idx = 0;
while(idx++ < 10000) {
count += 1;
}
}
}
// 竞态条件
public class Test {
private long count = 0;
synchronized long get(){
return count;
}
synchronized void set(long v){
count = v;
}
void add10K() {
int idx = 0;
while(idx++ < 10000) {
set(get()+1)
}
}
}
1.4.2 活跃性问题
活跃性问题有:“死锁”,“活锁”和“饥饿”
活锁: 有时线程虽然没有发生阻塞,但仍然会存在执行不下去的情况。一般是多线程同时竞争多个资源,一直出现碰撞导致都申请资源失败,然后不停重复发起。解决的方法就是在重新发起时添加随机等待时间
饥饿: 线程因无法访问所需资源而无法执行下去的情况。非公平锁容易出现有的线程一直得不到资源分配。
死锁: 一组互相竞争资源的线程因互相等待,导致“永久”阻塞的现象
1.4.3 性能问题
锁使访问共享资源的并行操作编程串行,降低了并行原有的高性能
阿姆达尔(Amdahl)定律:
n 可以理解为 CPU 的核数
p 可以理解为并行百分比
(1-p)就是串行百分比
如果我们的串行率是 5%,再假设 CPU 的核数(也就是 n)无穷大,那加速比 S 的极限就是 20。也就是说,那么我们无论采用什么技术,最高也就只能提高 20 倍的性能
所以:
- 既然使用锁会带来性能问题,那最好的方案自然就是使用无锁的算法和数据结构了
- 线程本地存储 (Thread Local Storage, TLS)
- 写入时复制 (Copy-on-write)
- 乐观锁等
- Java 并发包里面的原子类也是一种无锁的数据结构
- Disruptor 则是一个无锁的内存队列
- 减少锁持有的时间
- 细粒度的锁:ConcurrentHashMap的分段锁
- 读写锁,也就是读是无锁的,只有写的时候才会互斥
1.5 管程
1.6 java 线程的生命周期
线程的六种状态
- NEW(初始化状态)
- RUNNABLE(可运行 / 运行状态)
- BLOCKED(阻塞状态)
- WAITING(无时限等待)
- TIMED_WAITING(有时限等待)
- TERMINATED(终止状态)
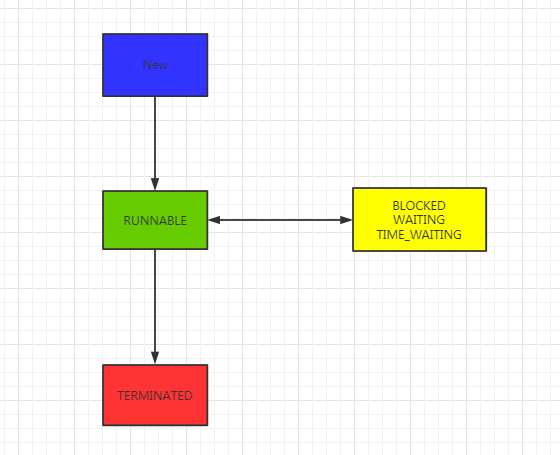
调用阻塞api线程的状态并不会改变,如等待io资源,对于cpu线程是休眠的,但是对于jvm线程仍旧是RUNNABLE。
-
NEW 与 RUNNABLE 的状态转换:
- 创建Thread对象时,状态为 NEW。
- Thread.start(); 状态为 RUNNABLE
-
RUNNABLE 与 BLOCKED 的状态转换:
- 等待与获得 synchronized 的隐式锁
-
RUNNABLE 与 WAITING 的状态转换:
- 获得 synchronized 隐式锁的线程,调用无参数的 Object.wait() 方法
- 调用无参数的 Thread.join() 方法(对应的线程执行完成时转换回RUNNABLE)
- 调用 LockSupport.park() 方法(LockSupport.unpark(Thread thread)转换回RUNNABLE)
-
RUNNABLE 与 TIMED_WAITING 的状态转换:
- 调用带超时参数的 Thread.sleep(long millis) 方法
- 获得 synchronized 隐式锁的线程,调用带超时参数的 Object.wait(long timeout) 方法;
- 调用带超时参数的 Thread.join(long millis) 方法
- 调用带超时参数的 LockSupport.parkNanos(Object blocker, long deadline) 方法
- 调用带超时参数的 LockSupport.parkUntil(long deadline) 方法
-
从 RUNNABLE 到 TERMINATED 状态
- run() 方法后,会自动转换到 TERMINATED 状态
- run() 过程中出现异常
- 强制中断
关于强制中断
强制中断一个线程可以使用 stop() 和 interrupt(), stop() 已经废弃。
对于 stop() 直接杀死线程,而 interrupt() 是给线程发送一个中断的信号量,有线程判断是否要中断。
- 处于 WAITING、TIMED_WAITING 状态的线程,如果其他线程调用该线程的 interrupt() 方法,会使该线程返回到 RUNNABLE 状态,同时线程 A 的代码会触发 InterruptedException 异常
- 让线程处于WAITING、TIMED_WAITING 状态的wait()、join()、sleep()方法 都有 InterruptedException 异常
- 如果是在无限循环的线程,并没有阻塞,代码可以通过 isInterrupted() 方法,检测是不是自己被中断了,做相应处理
- throw InterruptedException 后会重置中断标志,即:isInterrupted() 为 false
1.7 创建多少线程
提高吞吐量,简单延迟一般有两个方面:一个是优化算法,一个是充分利用硬件资源
多线程最大的作用就是充分利用硬件资源,在串行使用 cpu 和 io 时,总会有硬件空闲着,于是就需要多线程,能充分使用空闲的硬件资源
在CPU密集计算中,线程数理论上等于cpu核数(一般用 cpu 核数 + 1)
在 IO 密集计算中,一般 最佳线程数 =CPU 核数 * [ 1 +(I/O 耗时 / CPU 耗时)]
2. 并发工具类
2.1 Lock和Condition
Lock 用于解决互斥问题,Condition 用于解决同步问题
2.1.1 Lock
Lock 相对于 synchronized 来讲,解决了一下问题:
- 能够响应中断。 synchronized 的问题在于,线程持有锁 A 后尝试获取锁 B 失败,线程会进入阻塞状态,仍旧持有锁A,容易发送死锁。如果能响应中断,则可以多线程发出中断信号,释放锁A。这样就破坏了不可抢占条件了
- 支持超时。在一段时间之内没有获取到锁,直接返回错误,释放原先持有的其他资源。这样也能破坏不可抢占条件。
- 非阻塞地获取锁。 如果尝试获取锁失败,并不进入阻塞状态,而是直接返回,那这个线程也有机会释放曾经持有的锁。这样也能破坏不可抢占条件
Lock api 如下
java// 支持中断的API
void lockInterruptibly()
throws InterruptedException;
// 支持超时的API
boolean tryLock(long time, TimeUnit unit)
throws InterruptedException;
// 支持非阻塞获取锁的API
boolean tryLock();
2.1.1.1 可见性
多线程的可见性是通过 Happens-Before 规则保证的,而 synchronized 之所以能够保证可见性,也是因为有一条 synchronized 相关的规则:synchronized 的解锁 Happens-Before 于后续对这个锁的加锁。
而 Lock 靠什么保证可见性呢?
java
class X {
private final Lock rtl =
new ReentrantLock();
int value;
public void addOne() {
// 获取锁
rtl.lock();
try {
value+=1;
} finally {
// 保证锁能释放
rtl.unlock();
}
}
}
Lock 利用了 volatile 相关的 Happens-Before 规则
一个 volatile 变量的写操作, Happens-Before 于后续对这个 volatile 变量的读操作
ReentrantLock 内部实现中维护一个 volatile 修饰的变量 state 。(java.util.concurrent.locks.AbstractQueuedSynchronizer#state)取锁 和 解锁的时候,都会会读写 state 的值。而上述代码中 value+=1;前后都进行了 state 的读写,所以保证了 value+=1; Happens-Before 于 unlock 后的操作
-
顺序性规则:对于线程 T1,value+=1 Happens-Before 释放锁的操作 unlock();
-
volatile 变量规则:由于 state = 1 会先读取 state,所以线程 T1 的 unlock() 操作 Happens-Before 线程 T2 的 lock() 操作;
-
传递性规则:线程 T1 的 value+=1 Happens-Before 线程 T2 的 lock() 操作。class SampleLock { volatile int state; // 加锁 lock() { // 省略代码无数 state = 1; } // 解锁 unlock() { // 省略代码无数 state = 0; }}
三个用锁的最佳实践
永远只在更新对象的成员变量时加锁
永远只在访问可变的成员变量时加锁
永远不在调用其他对象的方法时加锁
2.1.2 Condition
Condition 实现了管程模型里面的条件变量
Lock 和 Condition 实现的管程,线程等待和通知需要调用 await()、signal()、signalAll(),它们的语义和 wait()、notify()、notifyAll() 是相同的
synchronized 管程模型中的条件变量只有一个,而使用 Lock 和 Condition 实现的管程可以使用多个条件变量
java
public class BlockedQueue<T>{
final Lock lock =
new ReentrantLock();
// 条件变量:队列不满
final Condition notFull =
lock.newCondition();
// 条件变量:队列不空
final Condition notEmpty =
lock.newCondition();
// 入队
void enq(T x) {
lock.lock();
try {
while (队列已满){
// 等待队列不满
notFull.await();
}
// 省略入队操作...
//入队后,通知可出队
notEmpty.signal();
}finally {
lock.unlock();
}
}
// 出队
void deq(){
lock.lock();
try {
while (队列已空){
// 等待队列不空
notEmpty.await();
}
// 省略出队操作...
//出队后,通知可入队
notFull.signal();
}finally {
lock.unlock();
}
}
}
2.1.3 Lock & Condition 使用
2.2 读写锁:ReadWriteLock
针对读多写少这种并发场景,Java SDK 并发包提供了读写锁——ReadWriteLock(实现类:ReentrantReadWriteLock)
通用读写锁一般有一下原则:
- 允许多个线程同时读共享变量;
- 只允许一个线程写共享变量;
- 如果一个写线程正在执行写操作,此时禁止读线程读共享变量。
java 的 ReentrantReadWriteLock 中包含着写锁 WriteLock 和读锁 ReadLock
ReadLock 为共享锁, WriteLock 为独占锁,两个锁互斥
ReadLock在单个变量的读写下看起来并没有什么用,在多个变量协同处理结果就很有用。
假设读取数据是 A+B 的结果,在没有读锁的情况下,并发修改了 A 值,B 值 还未修改,这时候读了 A+B 的结果,这时候就尝试了用 新的A值 加 旧的B值。这在很多场景下都是一个逻辑异常,因为我们要的是要么原来的 A+B 的结果或者新的 A+B 的结果
2.3 StampedLock
2.4 CountDownLatch和CyclicBarrier
2.5 并发容器
2.5.1 普通容器包装成并发容器
javaList list = Collections.synchronizedList(new ArrayList());
Set set = Collections.synchronizedSet(new HashSet());
Map map = Collections.synchronizedMap(new HashMap());
2.5.2 并发容器
2.5.2.1 List
CopyOnWriteArrayList:
原理: 内部维护一个数组 array , 在写的时候 CopyOnWriteArrayList 会将 array 复制一份,然后在新复制处理的数组上执行增加元素的操作,执行完之后再将 array 指向这个新的数组
CopyOnWriteArrayList 仅适用于写操作非常少的场景,而且能够容忍读写的短暂不一致
2.5.2.2 Map
ConcurrentHashMap 和 ConcurrentSkipListMap
主要区别在于 ConcurrentHashMap 的 key 是无序的,而 ConcurrentSkipListMap 的 key 是有序的,实现分段锁
需要注意的地方是,它们的 key 和 value 都不能为空,否则会抛出NullPointerException这个运行时异常
| 集合类 | key | value | 是否线程安全 |
|---|---|---|---|
| HashMap | 允许为 null | 允许为 null | 否 |
| TreeMap | 不允许为 null | 允许为 null | 否 |
| Hashtable | 不允许为 null | 不允许为 null | 是 |
| ConcurrentHashMap | 不允许为 null | 不允许为 null | 是 |
| ConcurrentSkipListMap | 不允许为 null | 不允许为 null | 是 |
2.5.2.3 Set
Set 接口的两个实现是 CopyOnWriteArraySet 和 ConcurrentSkipListSet,使用场景可以参考前面讲述的 CopyOnWriteArrayList 和 ConcurrentSkipListMap,它们的原理都是一样的,这里就不再赘述了。
2.5.2.4 Queue
队列比较复杂,分为 阻塞与非阻塞,有界无界,单端双端
阻塞队列都用 Blocking 关键字标识,单端队列使用 Queue 标识,双端队列使用 Deque 标识
常用的队列中只有 ArrayBlockingQueue 和 LinkedBlockingQueue 是支持有界的。
| 是否阻塞 | 是否有界 | 单端双端 | |
|---|---|---|---|
* 总结
互斥: 同一时刻,只能有一个线程进入临界区。这种情况称为互斥,即不允许多个线程同时对共享资源进行操作
同步: 多个线程通过协作的方式,对相同资源进行操作,这种行为称为同步。同步实际上就是线程间的合作,只不过合作时需要操作同一资源
现在有一个生产者和一个消费者,生产者负责生产资源,并放在盒子中,盒子的容量无限大;消费者从盒子中取走资源,如果盒子中没有资源,则需要等待。
这个问题涉及两个方面:互斥、同步(合作)。互斥是指同一时刻,只能有一方使用盒子。同步指的是消费者消费时,需要满足一个条件:盒子中的资源不为零,这个条件需要双方的合作才能完成,即消费者不能无限制地消费资源,需要在生产者生产的资源有剩余时才能进行消费。
消费者不仅受到盒子互斥锁的限制,还必须等到资源不为零时才可消费
三个用锁的最佳实践
永远只在更新对象的成员变量时加锁
永远只在访问可变的成员变量时加锁
永远不在调用其他对象的方法时加锁
读写锁通用规则:
- 允许多个线程同时读共享变量;
- 只允许一个线程写共享变量;
- 如果一个写线程正在执行写操作,此时禁止读线程读共享变量。
本文作者:Yui_HTT
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!