目录
1. 总述
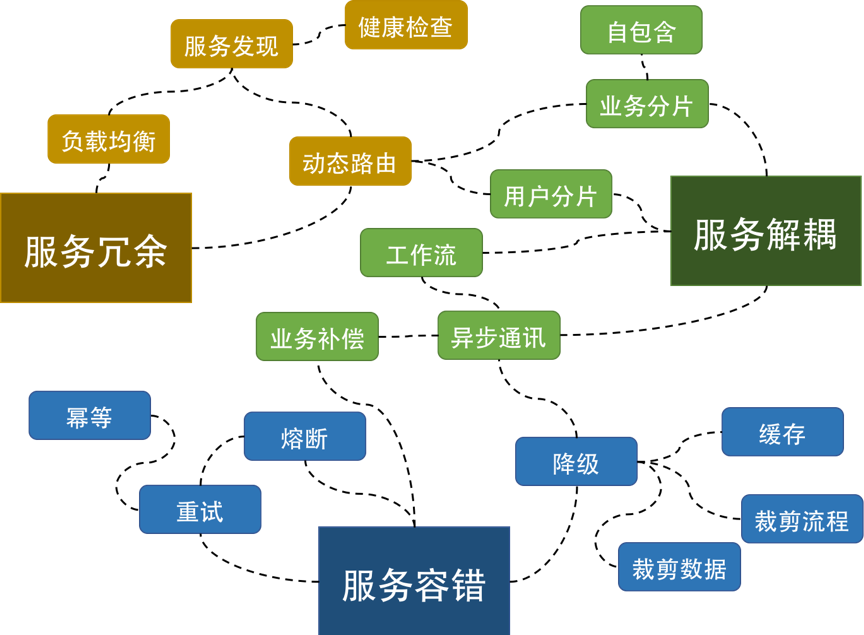
容错设计: 也叫弹力 (Resiliency)设计,包括容错能力(服务隔离、异步调用、请求幂等性)、可伸缩性(有 / 无状态的服务)、一致性(补偿事务、重试)、应对大流量的能力(熔断、降级)。
1.1 系统可用性测量
对于分布式的容错设计来讲,它是衡量一个系统在不健康,甚至出错时 处理问题的能力,也是一个系统可用性的指标
工业界有一条可用性指标公式用以计算可用性为:
其中:
MTTF是 Mean Time To Failure, 平均故障前时间,指系统平均正常运行多久才发送一次故障。MTTR是 Mean Time To Recovery, 平均修复时间,指从故障出现到故障修复的时间长度。- 额外概念:
MTBF是 Mean Time Between Failure,平均失效时间, 指系统两次故障发生时间之间的时间段的平均值
这个公式也是我们常说的几个9:
| 系统可用性% | 宕机时间/年 | 宕机时间/月 | 宕机时间/周 | 宕机时间/天 |
|---|---|---|---|---|
| 90%(1个9) | 36.5 天 | 72 小时 | 16.8 小时 | 2.4 小时 |
| 99%(2个9) | 3.65 天 | 7.20 小时 | 1.68 小时 | 14.4 分 |
| 99.9%(3个9) | 8.76 小时 | 43.8 分 | 10.1 分钟 | 1.44 分 |
| 99.99%(4个9) | 52.56 分 | 4.38 分 | 1.01 分钟 | 8.66 秒 |
| 99.999%(5个9) | 5.26 分 | 25.9 秒 | 6.05 秒 | 0.87 秒 |
由上述公式可得
要提高系统的可用性,要么增加无故障时间,要么减少修复时间
1.2 故障原因
- 有计划故障:
- 日常任务:备份,容量规划,用户和安全管理,后台批处理应用。
- 运维相关:数据库维护、应用维护、中间件维护、操作系统维护、网络维护。
- 升级相关:数据库、应用、中间件、操作系统、网络,包括硬件升级。
- 无计划故障:
- 系统级故障,包括主机、操作系统、中间件、数据库、网络、电源以及外围设备。
- 数据和中介的故障,包括人员误操作、硬盘故障、数据乱了。
- 还有自然灾害、人为破坏,以及供电问题等。
- 故障分类:
- 网络问题。网络链接出现问题,网络带宽出现拥塞……
- 性能问题。数据库慢 SQL、Java Full GC、硬盘 IO 过大、CPU 飙高、内存不足……
- 安全问题。被网络攻击,如 DDoS 等。
- 运维问题。系统总是在被更新和修改,架构也在不断地被调整,监控问题……
- 管理问题。没有梳理出关键服务以及服务的依赖关系,运行信息没有和控制系统同步……
- 硬件问题。硬盘损坏、网卡出问题、交换机出问题、机房掉电、挖掘机问题……
1.3 容错的必要性
在分布式系统中故障是不可避免的,而系统的容错能力就是为了尽一切手段来降低 MTTR
- 一方面正常情况下进行自动修复,无需人为干预
- 自动修复不了,能够进行自我保护,不然异常扩大
2. 隔离设计
2.1 概述
隔离设计来源于英文单词的 Bulkheads ,中文翻译为隔板。在船上,船舱也有隔板设计,通过隔板把船舱分为多个空间,用来控制船舱漏水的影响范围。
在系统设计过程中,也常会用隔离设计来保证系统故障时的影响范围。对于隔离设计一般会有以下两种方式:
- 以服务种类来做隔离
- 以用户请求来做隔离
2.2 以服务种类隔离
微服务架构主要的设计就是服务隔离,即把不同的业务功能独立成单独的应用,比如:用户中心,订单数据等。它们可以通过使用不同的域名,服务器,数据库等资源,来进行一个隔离,其中任意一个应用的故障不会影响到其他应用的使用。
这个隔离机制存在的问题:
- 同时需要用到多个服务的情况下,响应时间更长
- 数据分析时,数据聚合麻烦(数据中台)
- 跨应用时,一个应用故障也会导致流程不通(通过 Step-by-Step 解决)
- 会有分布式事物问题(Plan – Reserve – Commit/Cancel 模式)
- 消息交互问题(消息队列)
这样的系统通常会引入大量的异步处理模型
2.3 以用户请求隔离
把用户分成不同的组,根据不同组把服务分成不同实例,让于同一个服务针对不同用户组进行冗余和格力。这样即使服务实例故障,也只影响对应的组。这就是所谓的 ”多租户“模式
使用多租户架构会使设计变得复杂,而且设计的不好会导致资源浪费
一般多租户有以下做法:
- 完全独立。每个租户有完全独立的服务和数据
- 服务共享,数据分离
- 共享服务,共享数据。
一般来说,越独立资源越浪费,设计越简单。所以使用第二种方案更为合适,当对于特别重要得用户,可以使用完全独立的做法。
而在容器云快速发展的今天,使用容器技术来做到完全独立时也不浪费资源。
3. 异步通讯设计
3.1 概述
在对系统做解耦设计(面向隔离设计需要)时,通常需要面对就是不同系统间的一个通讯设计。
通信一般有两种方式:同步通讯,异步通讯
- 同步通讯:消息实时响应,实时性高,耦合性高
- 异步通讯:消息异步响应,实时性低,耦合性低
同步通讯带来的问题
- 调用方和被调用方性能不一致,导致被调用方系统崩溃或浪费
- 等待响应占用调用方资源
- 被调用方异常,影响调用方
异步通讯带来更好的解耦,让各方用自己的性能完成自己的业务
3.2 异步通讯的三种方式
3.2.1 请求响应式
调用方向被调用方发起请求,被调用方记录任务,返回处理中(一般不可识别数据会带有任务id)。
接下来会有两种情况:
- 调用方间隔地去请求被调用方任务的结果,直至处理完成
- 被调用方处理完成,回调回调用方,发送请求结果
3.2.2 通过订阅方式
接收方(receiver)会来订阅发送方(sender)的消息,发送方会把相关的消息或数据放到接收方所订阅的队列中,而接收方会从队列中获取数据
这种方式下,sender 并不关心 receiver 的处理结果,只是告诉 receiver 需要处理数据
这种方式与前面方式的不同在于,前面的方式数据是有来有往,服务是由状态的。而订阅方式,服务是无状态的(通过第三方的状态服务来保证),那么服务只能依赖于事件
事件通讯是异步通讯中最重要的一个设计模式。
这种方式,接收方需要向发送方订阅事件,所以是接收方依赖于发送方。还是存在耦合性
3.2.3 通过 Broker 的方式
与订阅方式类似,在接收方和发送方中间增加一个 broker ,用以处理数据队列,让接收方和发送方完全解耦,只关注队列
broker 必须要有以下特性
- 必须是高可用的,因为它成了整个系统的关键;
- 必须是高性能而且是可以水平扩展的;
- 必须是可以持久化不丢数据的。
4. 幂等性设计
4.1 概述
在调用方和被调用方做异步通讯时,由于各种原因(如超时)出现导致重复请求(重复消息),一般有以下解决方法:
- 由下游系统提供查询接口,上游系统调用下游系统出现超时时,上游系统查询记录看是否已经调用成功,根据查询结果决定是否重新发起请求
- 下游系统增加幂等性设计。无论上游发起多少次请求,对于下游系统都是一样的,返回同样的结果。相当于,查询操作由下游自己完成
4.2 全局 ID
要做到幂等性的交易接口,需要有一个唯一的标识,来标志交易是同一笔交易
全局id一般有以下做法
- id 中心系统:弊端是增加开销
- 上游系统创建:id重复
- UUID:太长,占用空间大,索引效率低
- Snowflake:毫秒时间(41bit)+ 集群编码(10bit,5bit 数据中心 + 5bit 机器id)+ 毫秒内序列号(12bit)
4.3 处理流程
- 接受到请求后,先查询数据状态,未处理过的,处理,已经处理过的返回处理结果
- 接受到请求后,直接处理数据,通过inster主键冲突或update条件判断,来处理
4.4 http 的幂等性
- HTTP GET 方法用于获取资源,不应有副作用,所以是幂等的
- 幂等不代表结果是一样的,而是每次的作用是一样的
- HTTP HEAD 和 GET 本质是一样的,区别在于 HEAD 不含有呈现数据,而仅仅是 HTTP 头信息,不应用有副作用,也是幂等的
- HEAD 常用于探活
- HTTP OPTIONS 主要用于获取当前 URL 所支持的方法,所以也是幂等的
- HTTP DELETE 方法用于删除资源,有副作用,但它应该满足幂等性
- 多次delete,也不会引发异常
- HTTP POST 方法用于创建资源,所对应的 URI 并非创建的资源本身,而是去执行创建动作的操作者,有副作用,不满足幂等性
- 如创建新的文章等等
- HTTP PUT 方法用于创建或更新操作,所对应的 URI 是要创建或更新的资源本身,有副作用,它应该满足幂等性。
5. 服务的状态
6. 补偿事务
6.1 ACID 和 BASE
传统关系型数据系统的事务都有 ACID 属性:
- 原子性(Atomicity): 事务的过程中的操作要么全部成功,要么全部失败。发送错误是 Rollback 到事物开始前的状态
- 一致性(Consistency):在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏
- 隔离性(Isolation,又称独立性):不同事务之间互不干扰,也看不同事务过程中的数据
- 持久性(Durability):在事务完成以后,该事务对数据库所做的更改便持久地保存在数据库之中,并不会被回滚。
事务的 ACID 属性保证了数据库的一致性,但是对于分布式系统来说(尤其是微服务),ACID 很难去保证高性能要求的。于是为了满足性能要求,提出了一个 ACID 的变种 BASE (BASE是对CAP中一致性和可用性权衡的结果)
-
Basic Availability:基本可用。这意味着,系统可以出现暂时不可用的状态,而后面会快速恢复。
-
Soft-state:软状态。它是我们前面的“有状态”和“无状态”的服务的一种中间状态。也就是说,为了提高性能,我们可以让服务暂时保存一些状态或数据,这些状态和数据不是强一致性的。
-
Eventual Consistency:最终一致性,系统在一个短暂的时间段内是不一致的,但最终整个系统看到的数据是一致的。
BASE 系统是允许或是容忍系统出现暂时性问题的
在分布式中,故障是不可避免的,所以我们要做到 Design for Failure,也就是把故障处理当成功能写到代码中
ACID 和 BASE 举例:
- ACID: 买书,请求,排队,获取库存锁,库存变更,购买成功,释放库存锁,下一个人获取库存锁
- BASE:买书,下单,下单成功,异步处理库存,存在库存,下单成功。库存用尽,通知用户没有购买成功
对于 BASE 方式,在亚马逊购买东西的时候就是这样的
在亚马逊上买东西,你会收到一封邮件说,系统收到你的订单了,然后过一会儿你会收到你的订单被确认的邮件,这时候才是真正地分配了库存。所以,有某些时候,你会遇到你先收到了下单的邮件,过一会又收到了没有库存的致歉的邮件
ACID强调的是一致性(CAP 中的 C),而BASE强调的是可用性(CAP 中的 A)。
6.2 补偿事务(TCC)
当条件不满足,或是有变化的时候,需要从业务上做相应的整体事务的补偿
业务补偿,首先需要把服务做成幂等性的,失败或超时需要不停重试。如果无法到达要的状态,可以回滚成上一个状态。如果有更新的请求,需要更新整个事务的业务
(这块也是分布式事务的内容)
详细可参考:分布式容错之分布式事务
7. 重试设计
8. 熔断设计
8.1 概述
熔断设计:
- 为了防止应用程序不断尝试执行可能失败的操作,浪费 CPU 时间
- 诊断错误是否已经修正
熔断器可以使用状态机来实现,内部模拟以下状态
- 闭合(Closed)状态: 该状态下,请求正常访问。内部存在一个错误计数器,当限定时间内错误数达到一定阈值时,切换到 open 状态。开启超时时钟,时钟超过该时间,切换到 Half-Open 状态。这个超时时间的设定时用来修正导致失败的错误,以恢复正常工作状态。
- 断开(Open)状态:在该状态下,请求会立即返回错误响应,而不调用后端服务。也可以选择 cache 上次成功的请求,直接返回请求。
- 半开(Half-Open)状态: 通过一定量的请求,如果请求调用成功,认为错误修复了,恢复到闭合状态。如果存在失败调用,则切回 open 状态,重置超时时钟。
熔断器通过每次切换状态的时候发出一个事件,用来监控服务的运行状态,达到告警通知的作用
Hystrix 实现逻辑(参考文档)
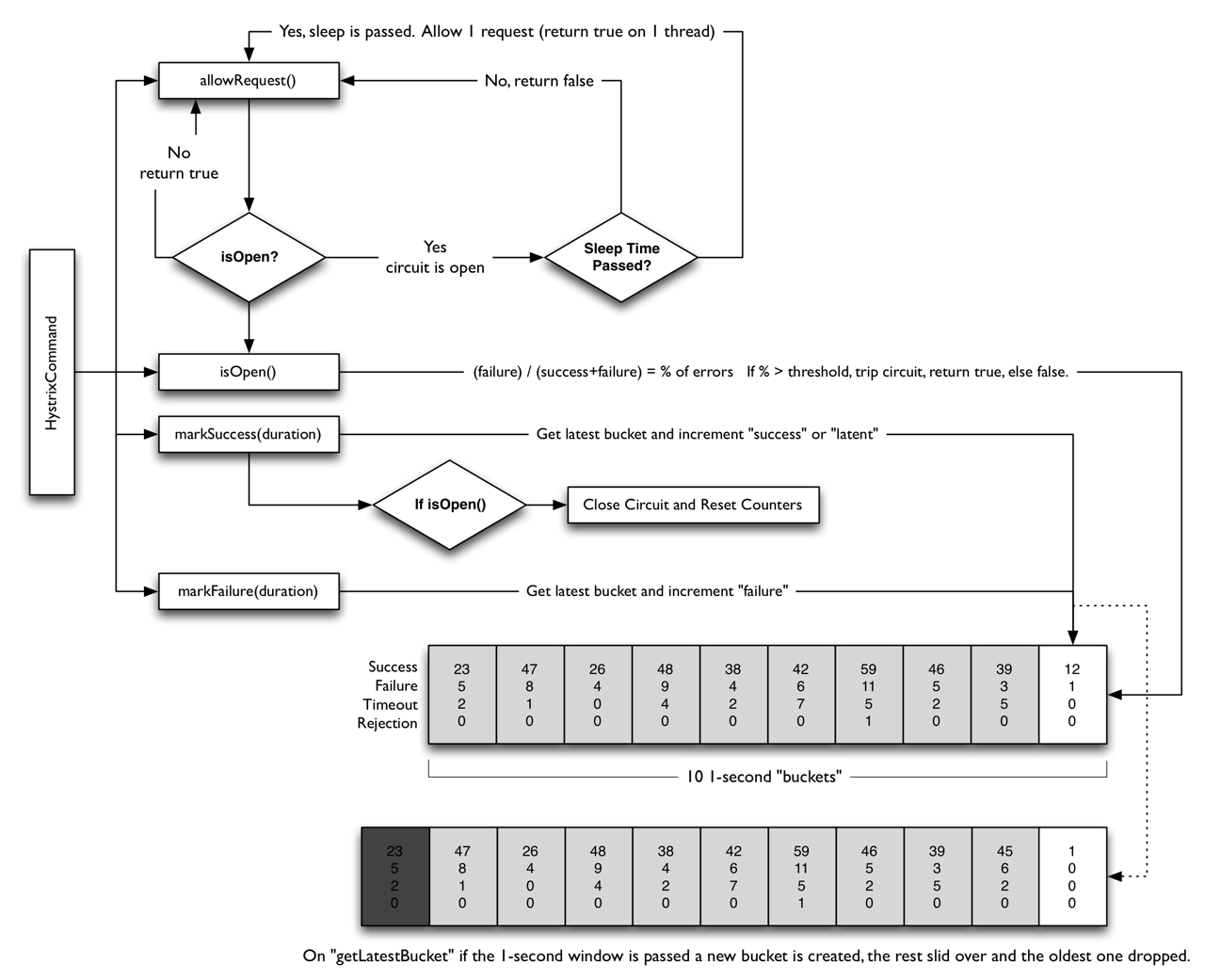
- 请求进来,allowRequest()函数判断是否在熔断中,如果不是这放行;如果是,检查是否到达一个熔断时间片,如果时间片到了,也放行,否则自己返回出错。
- 每次调用都有两个函数 markSuccess(duration) 和 markFailure(duration) 来统计一定时间内的失败和成功数
- 判断是否熔断的条件 isOpen(),是计算 failure/(success + failure) 当前错误率,高于阈值这打开熔断,否则关闭
- Hystrix 会在内存中维护一个数组,其中记录着每一个周期的请求结果的统计。超过时长长度的元素会被删除掉。
8.2 熔断设计的重点
- 错误的类型。熔断和重试一样,需要对返回的错误进行识别。一些错误需要走重试策略,一些则直接打开熔断器。
- 日志监控。需要记录所有失败的请求。已经一些可能会尝试成功的请求,用于管理员监控使用熔断器保护服务的执行情况。
- 测试服务是否可用。在断开状态下,熔断器可以采用一些方式(如 ping)来测试远程服务的健康检查接口,来判断是否恢复服务,而不一定使用半开状态,半开状态在服务恢复后需要用户流量来完成状态转换,会有部分流量不可用。
- 手动重置。提供手动强制闭合和断开的功能。用于管理员手动操作。
- 并发问题。熔断器不应该对请求造成负担,尤其统计结果最好使用无锁的数据结构。
- 资源分区。在资源分区的服务上(如,数据库分库分表),某个分区出现问题,熔断器如果是针对所有分区进行结果统计,可能会导致熔断器频繁断开闭合。需要考虑熔断器对不同分区进行熔断,而不是对整体熔断
- 重试错误的请求。有时候,错误和请求的数据和参数有关系,所以,记录下出错的请求,在半开状态下重试能够准确地知道服务是否真的恢复。当然,这需要被调用端支持幂等调用,否则会出现一个操作被执行多次的副作用。
9. 限流设计
9.1概述
限流的目的是通过对并发访问进行限速
一般是达到限制速率会触发相应的策略,限流策略如下:
- 拒绝服务。 拒绝多的请求,更好的做法是拒绝高流量客户端请求,可以防止攻击。
- 服务降级。 把后端服务关闭或降级处理,让出资源去处理请求。降级有多种方式,一种是把不重要服务停掉,让出资源;一种是不返回全量数据,值返回部分数据;还有一种是返回预设缓存,牺牲一致性换取吞吐量。
- 特权请求。 资源不够时,重要用户请求优先。
- 延时处理。 利用队列缓冲大量的请求,队列满了之后拒绝服务。
- 弹性伸缩。 动用自动化运维的方式对相应的服务做自动化的伸缩。
9.2 限流的实现方式
计数器方式
最简单的限流方式就是维护一个计数器 Counter,请求进来是+1,请求完成后-1。当计数器超过限定阈值的时候,触发限流操作。
队列算法
- 用 FIFO 队列来存放请求,顺序处理
- 用双FIFO队列(一个普通用户,一个特权用户)来存放请求,顺序处理
- 用多个队列存放请求,用加权的方式分配不同的处理数到不同的队列
这样的算法需要用队列长度来控制流量,在配置上比较难操作。如果队列过长,导致后端服务在队列没有满时就挂掉了。一般来说,这样的模型不能做 push,而是 pull 方式会好一些。
漏斗算法 Leaky Bucket
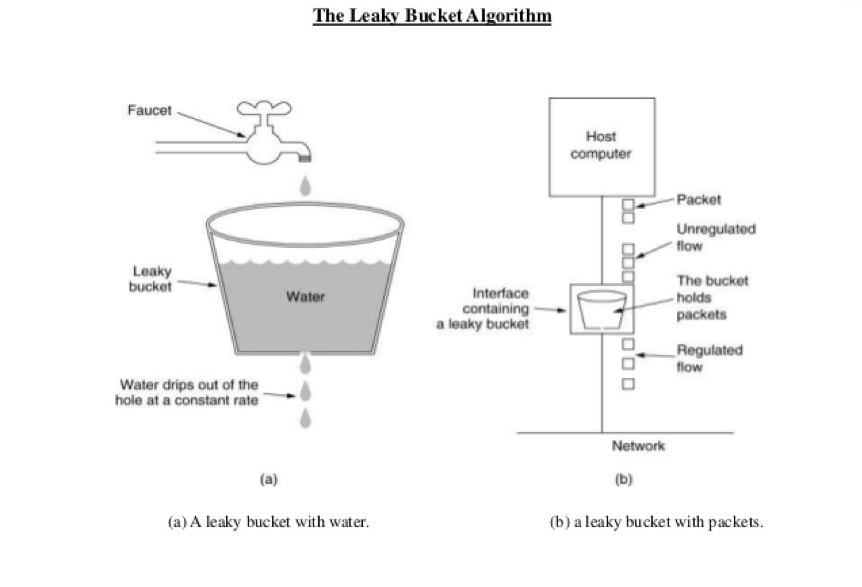
如图,以漏斗底部作为速率的最大入口,当速率到达阈值,后面请求会被置入漏斗中,匀速通过漏斗底部。当水越积越多,就会溢出。
一般来说,这个“漏斗”是用一个队列来实现的,当请求过多时,队列就会开始积压请求,如果队列满了,就会开拒绝请求。(漏斗算法的实现,就是在 FIFO 队列后面加个限流器,让程序能在到达最大速率时匀速处理请求。)
在 TCP 中,当请求的数量过多时,就会有一个 sync backlog 的队列来缓冲请求,或是 TCP 的滑动窗口也是用于流控的队列。
令牌桶算法 Token Bucket
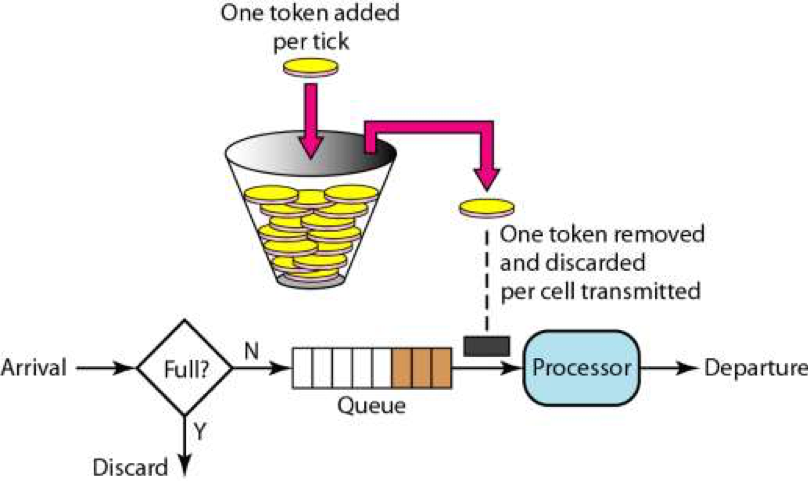
令牌桶的步骤大致如下:
- 由中间人(特定线程)往桶里放 token,token 的数量上线是桶的大小(一般为服务的 QPS),例如:限速每秒100个请求,则可以设置生产速率为每10ms一个,直到满100个。
- 请求进来,从桶里拿出一个 token 消费,拿到 token 继续请求,拿不到拒绝
与漏斗算法相比,漏斗算法是恒定速率通过请求,而令牌桶在空闲是积攒令牌,突发大流量是,可以瞬间通过限定速率的请求,之后以生产token的速率,通过请求。
基于响应时间的动态限流
对于上面的限流方式,都需要先性能测试出对应的速率作为阈值,而资源(数据库,cpu,硬盘)是不稳定的,会发生变化的;不同的接口阈值也是不一样的;而现在的自动化伸缩技术也导致阈值的变化;基于多方面考虑限流的值是很难被静态地设置成恒定的一个值。
基于响应时间的动态限流: 类似 TCP 使用 RTT - Round Trip Time 来探测网络的延时和性能,从而设定相应的“滑动窗口”的大小,以让发送的速率和网络的性能相匹配
设计要点:
- 需要计算 P90 或 P99:这个过程很耗费CPU和内存;可以通过两种方式处理:1.使用采样处理;2.蓄水池的近似算法(Reservoir Sampling)
- 记录当前的 QPS,发现 P90 或 P99 响应太慢,QPS 减半再启动,直到调整到合适的值
- 参考资料:Reservoir Sampling, TCP 的那些事儿-陈皓
9.3 限流设计要点
限流的目的:
- 为了向用户承诺 SLA。 保证再某个速度下的响应时间以及可用性
- 多租户情况下,对每个租户进行限流,反正单个用户影响整个系统
- 应付突发的流量
- 节约成本。 削峰填谷
设计的考量:
- 限流应该是在架构的早期考虑。当架构形成后,限流不是很容易加入
- 限流模块性能必须好,而且对流量的变化也是非常灵敏的
- 限流应该有个手动的开关,这样在应急的时候,可以手动操作
- 当限流发生时,应该有个监控事件通知
- 可以自动化触发扩容或降级,以缓解系统压力
- 限流应该让后端的服务感知到。比如 HTTP Header 中,放入一个限流的级别。方便后端觉得是否降级处理
10. 降级设计
10.1 概述
所谓的降级设计(Degradation),本质是为了解决资源不足和访问量过大的问题。
降级一般需要牺牲的东西有:
- 降低一致性。 从强一致性变成最终一致性。
- 简化流程的一致性
- 降低数据的一致性
- 停止次要功能。 停止访问不重要的功能,从而释放出更多的资源。
- 先限制次要功能的流量
- 或者把次要功能退化成简单功能
- 如果量太大才进入停止功能的状态
- 简化功能。 把一些功能简化掉,比如,简化业务流程,或是不再返回全量数据,只返回部分数据。
- 比如只返回商品信息,不返回评论
降级设计的要点:
- 梳理 must-have 的功能和 nice-to-have 的功能
- 牺牲一致性:读操作可以使用缓存,写操作可以使用异步调用
- 降级的功能的开关可以是一个系统的配置开关
- 降级的功能平时不会总是会发生,属于应急的情况
本文作者:Yui_HTT
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!