目录
redis base
1. 数据淘汰策略
通常地,再内存足够的情况下,使用过期策略对 key 的过期进行管理,而当内存使用达到限制时,会使用内存淘汰 进行管理
1.1 过期策略
参考: redis expire
定期删除+惰性删除
redis 在使用时,可以对一个 key 设置过期时间(设置了过期时间的key,一般称为 volatile),到期之后怎么删除呢?使用 定期删除+惰性删除
shellEXPIRE <KEY> <TTL> : 将 key 的生存时间设置为 ttl 秒 PEXPIRE <KEY> <TTL> : 将 key 的生存时间设置为 ttl 毫秒 EXPIREAT <KEY> <timestamp> : 将 key 的过期时间设为 timestamp 所指定的秒数时间戳 PEXPIREAT <KEY> <timestamp> : 将 key 的过期时间设为 timestamp 所指定的毫秒数时间戳 TTL <KEY> : 返回剩余生存时间 ttl 秒 PTTL <KEY> : 返回剩余生存时间 pttl 毫秒 RERSIST <KEY> : 移除一个键的过期时间
Redis keys are expired in two ways: a passive way, and an active way
1.1.1 惰性删除(passive way)
A key is passively expired simply when some client tries to access it, and the key is found to be timed out.
当客户端访问一个 key 时,会先检查是否存在过期时间?是否已经过期?如果过期则删除
1.1.2 定期删除(active way)
如果只使用 passive way ,那么会导致有些过期后,不再被访问的 key 会一直留在内存空间。于是就有了 定期删除 的方式
- redis 每100ms会做10次以下操作
- 随机测试 20 个设置过期时间的 keys
- 删除所有被判断为过期的 key
- 如果超过 25% 个 key 是过期的,那么重复步骤1
This means that at any given moment the maximum amount of keys already expired that are using memory is at max equal to max amount of write operations per second divided by 4.
1.2 内存淘汰
参考:lru-cache
1.2.1 Maxmemory configuration directive
在 redis 配置中,通过使用 maxmemory 配置 redis 使用内存大小的现在,可以通过 启动前配置配置文件 redis.conf,或者 启动后执行命令 CONFIG SET 来进行设置
如果配置为 0,则在内存使用上没有限制(在 64 位系统上来讲是这样的,32位会有隐式限制为3GB)
当内存使用达到配置限制时,会根据策略的选择做不同的处理
1.2.2 内存淘汰策略(Eviction policies)
使用 maxmemory-policy 配置,配置策略
- noeviction:当内存达到限制时,客户端提交会使内存超出限制的指令时,返回异常
- allkeys-lru: 通过尝试删除最近使用较少的key (LRU)来为新的数据腾出空间
- volatile-lru: 通过尝试删除最近使用较少的设置了过期时间的key (LRU)来为新的数据腾出空间
- allkeys-random: 通过随机删除 key 来为新的数据腾出空间
- volatile-random: 通过随机删除设置了过期时间的 key 来为新的数据腾出空间
- volatile-ttl: 优先删除具有过期时间且过期时间较短的 key
1.2.3 内存回收线程如何工作
- 步骤如下:
- 客户端运行一个新命令,导致数据增加
- redis 检查内存使用,如果超过 maxmemory 限制,使用回收策略进行回收
- 一个新命令被执行,以此类推
所以内存会不停地在内存限制区,不停地超出限制和返回限制下。如果提交一个大的数据,在某些时候会造成内存使用明显超出限制。
1.3 LRU - Least Recently Used
1.3.1 LRU 步骤
-
步骤:
- 新数据直接插入到列表头部
- 缓存数据被命中,将数据移动到列表头部
- 缓存已满的时候,移除列表尾部数据。
-
画图:
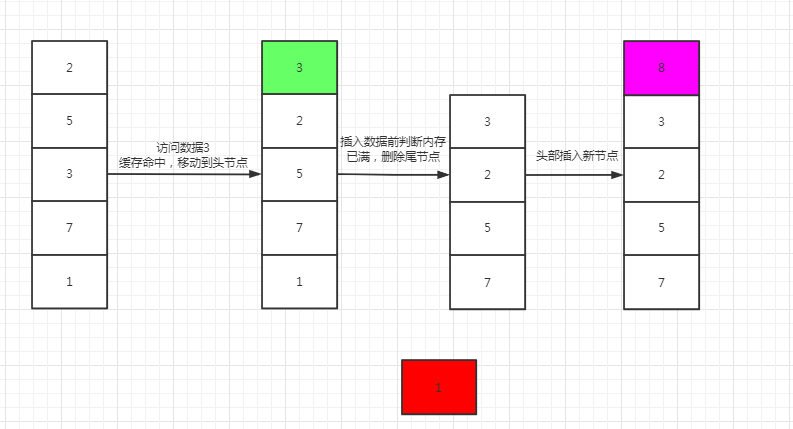
1.3.2 LRU - 数据结构
对于 LRU 的数据结构,需要做到的是,保存有序,移动节点,添加节点(头结点),删除节点(尾节点),一般用于缓存所以需要保证查找的算法复杂度足够低。一般常用 双向链表 + Hash散列 来作为 LRU 的数据结构(这个结构也是 java 集合中 LinkedHashMap 数据结构的实现)
简单实现
javapackage com.yui.study.algorithms.base.dto;
import lombok.Data;
import lombok.experimental.Accessors;
import java.util.HashMap;
import java.util.Map;
/**
* @author YUI_HTT
* @date 2021/3/30
*/
public class LruCache<K, V> {
private Entry<V> head, tail;
int capacity;
int size;
private Map<K, Entry<V>> cache;
@Data
@Accessors(chain = true)
public static class Entry<T> {
private Entry<T> preNode;
private Entry<T> nextNode;
private T value;
}
public LruCache(int capacity) {
this.capacity = capacity;
this.size = 0;
this.head = new Entry<>();
this.tail = new Entry<>();
this.head.nextNode = this.tail;
this.tail.preNode = head;
cache = new HashMap<>(capacity);
}
/**
* 放入元素
* @param key
* @param value
*/
public void put(K key, V value){
Entry<V> newNode = this.cache.get(key);
if (newNode != null){
moveToHead(newNode);
newNode.value = value;
return;
}
if (size == capacity){
removeTail(key);
}
newNode = new Entry<>();
newNode.value = value;
addNode(newNode);
this.cache.put(key, newNode);
size++;
}
public V get(K key){
Entry<V> node = this.cache.get(key);
if (node == null){
return null;
}
moveToHead(node);
return node.value;
}
public void moveToHead(Entry<V> node){
deleteNode(node);
addNode(node);
}
public void removeTail(K key){
deleteNode(this.tail.preNode);
this.cache.remove(key);
size--;
}
public void addNode(Entry<V> node){
this.head.nextNode.preNode = node;
node.preNode = this.head;
node.nextNode = this.head.nextNode;
this.head.nextNode = node;
}
public void deleteNode(Entry<V> node){
node.preNode.nextNode = node.nextNode;
node.nextNode.preNode = node.preNode;
}
public void display() {
Entry<V> currentNode = this.head.nextNode;
if(currentNode == null) {
return;
}
while (currentNode.nextNode != null) {
System.out.print(currentNode.value + "\t");
currentNode = currentNode.nextNode;
}
System.out.println("");
}
public static void main(String[] args) {
LruCache<String, String> cache = new LruCache<>(5);
cache.put("test1", "1");
cache.put("test2", "2");
cache.put("test3", "3");
cache.put("test4", "4");
cache.put("test5", "5");
cache.display();
System.out.println(cache.get("test3"));
cache.display();
System.out.println(cache.get("test5"));
cache.display();
cache.put("test6", "6");
cache.display();
}
}
运行结果如下:
text5 4 3 2 1 3 3 5 4 2 1 5 5 3 4 2 1 6 5 3 4 2
1.3.3 拓展1:LRU-K
1.3.4 拓展2:2Q
1.3.5 拓展3: LIRS
1.4 LFU
2. 数据结构
2.1 内部数据结构
| 数据结构 | 内部编码 | 内部结构 | 优劣性 |
|---|---|---|---|
| string | int | 8 个字节的 长整型 | |
| embstr | 小于等于 39 个字节的字符串 | ||
| raw | 大于 39 个字节的字符串 | ||
| hash | ziplist | 1.元素个数小于配置hash-max-ziplist-entries(默认512)2.所有的值小于配置 hash-max-ziplist-value 配置(默认 64 字节)时同时满足1,2点 | 更加 紧凑的结构 实现多个元素的 连续存储,使用内存更少 |
| hashtable | 无法满足 ziplist 的条件时 | 读写效率更高 | |
| list | ziplist | 1.元素个数小于配置 list-max-ziplist-entries (默认 512 个)2.同时列表中 每个元素 的值都 小于 list-max-ziplist-value 配置时(默认 64 字节)同时满足1,2点 | 更加 紧凑的结构 实现多个元素的 连续存储,使用内存更少 |
| linkedlist | 无法满足 ziplist 的条件时 | ||
| set | intset | 1.元素都是整数 2.元素个数小于配置 set-max-intset-entries(默认 512 个)同时满足1,2点 | 使用内存更少 |
| hashtable | 无法满足 intset 的条件时 | ||
| zset | ziplist | ||
| skiplist |
2.2 使用场景
- string
- 缓存
- 计数:
incr - 共享 session
- 限速:单位时间内调用次数
- hash
- 关系型数据缓存:比如人员信息
- list
- Stack(栈):
lpush + lpop - Queue(队列):
lpush+rpop - Capped Collection(有限集合):
lpush + ltrim - Message Queue(消息队列):
lpush + brpop
- Stack(栈):
- set
sadd标签(tag):比如用户画像,人群分类,文章分类spop/srandmember: 生成随机数,比如抽奖sadd + sinter: 社交需求
- zset
- 排行版,去TopN操作
- 带权重的消息队列
3. redis 集群模式
3.1 redis 集群方案
3.1.1 客户端分区方案
由客户端决定数据所属(写/读)的节点,一般是采用 hash 算法对 key 进行计算
客户端分区方案的代表为 Redis Sharding , 这是在 Redis Cluster 出来之前,业界普遍使用的 Redis 多实例集群 方法。
java 的客户端驱动库 jedis, 就是 Redis Sharding + 缓存池 ShardedJedisPool
-
优点
- 不用需要使用第三方中间件
- 分区逻辑可控
- 配置简单
- 节点间没有关联,容易线性扩展
-
缺点
- 客户端无法动态增删服务节点
- 需要自行维护分发逻辑
- 客户端无连接共享,造成连接浪费
3.1.2 代理分区方案
客户端 发送请求到一个 代理组件,代理 解析 客户端 的数据,并将请求转发至正确的节点,最后将结果回复给客户端
-
优点:
- 简化 客户端 的分布式逻辑
- 客户端 透明接入,切换成本低
- 代理的 转发 和 存储 分离。
-
缺点:多了一层 代理层,加重了 架构部署复杂度 和 性能损耗。
代理分区 主流实现的有方案有 Twemproxy 和 Codis。
3.1.2.1 拓展:Twemproxy
3.1.2.2 拓展:Codis
3.1.3 查询路由方案
客户端随机地请求任意一个 Redis 实例,然后由 Redis 将请求转发给正确的 Redis 节点.
Redis Cluster 实现了一种 混合形式 的 查询路由, 不是由节点转发,而是在 客户端 的帮助下直接 重定向(redirected)
- 优点
- 没有中心节点
- 可以平滑地进行节点 扩容/缩容
- 支持 高可用 和 自动故障转移
- 运维成本低
- 缺点
- 严重依赖
Redis-trib工具,缺乏 监控管理 - 依赖于
Smart Client- 维护连接
- 缓存路由表
- MultiOp 和 Pipeline 支持
Failover节点检测过慢,不如中心接线zookeeper及时Gossip消息具有一定开销- 无法根据统计区分 冷热数据
- 严重依赖
3.2 数据分布理论
3.2.1 分布式数据分布
对于分布式数据库来讲,需要解决的一个重要问题就是,要解决 整个数据集 按照 分区规则 映射到 多个节点 的问题。即如何把数据集分配到多个节点上,由每个节点负责一个子集
数据的分布规则通常由 哈希分区 和 顺序分区 两种方式,其对比如下:
| 分区方式 | 特点 | 相关产品 |
|---|---|---|
| 哈希分区 | 离散程度好 数据分布与业务无关 无法顺序访问 | Redis Cluster Cassandra Dynamo |
| 顺序分区 | 离散程度易倾斜 数据分布与业务相关 可以顺序访问 | BigTable HBase Hypertable |
Redis Cluster 使用的为 哈希分区,所以这里主要讨论 哈希分区
3.2.1.1 哈希分区之节点取余分区
使用特定数据进行计算出 hash 值,再模以节点数,来得到数据落点
-
对于redis key 在 N 个节点的集群上可以计算为:
hash(key) % N -
针对这种方式的扩缩容:
- 最佳为扩缩容为当前节点数的N倍,这样需要迁移50%的数据
- 扩缩容都需要进行数据迁移,最差需要迁移所有数据
-
优点:
- 规则简单,常用于数据库的分库分表规则
- 一般会采用 预分区 的方式,提前规划好 数据量 和 分区数
-
缺点:
- 节点数发生变化时,需要重新计算 映射关系,迁移数据
- 通常需要采取翻倍扩容,避免所有数据落点被打乱
3.2.1.2 哈希分区之一致性哈希分区
-
步骤如下:
- 首先构建一个hash值闭环,通常是0~2^32,即0和2^32重合形成一个环
- 将各节点的特定数据(如节点ip,服务器名,节点名等)进行 hash 计算获取各个节点的hash值,落在hash环中
- 存储数据是,用该数据的特定数据(如key,id等)计算出该数据的hash值
- 用数据的hash值,顺时针寻找到最近的节点,该节点就是该数据的落点
-
扩缩容:
-
扩容时需要计算新节点的落点,该落点的数据(落点前一个节点A到落点后一个节点B区间的数据)本为B节点管理,新增节点后需要调整为A节点到新落点的数据为新落点管理,新落点的到B节点的数据为B节点管理。即:分担落点的后一个相邻节点的数据
graph LR; T1[ ] --- A A[节点A] --- D1[data1] D1 --- D2[data2] D2 --- D3[data3] D3 --- D4[data4] D4 --- B[节点B] B --- T2[ ]graph LR; T1[ ] --- A A[节点A] --- D1[data1] D1 --- D2[data2] D2 --- C[节点C] C --- D3[data3] D3 --- D4[data4] D4 --- B[节点B] B --- T2[ ] -
缩容也是则相反的,把要释放的节点负责的数据交由后一个相邻节点管理
-
所以扩容和缩容所影响的只有对应节点的后一个相邻节点
-
-
优点:
- 节点发生变化时,只会影响哈希环中顺时针相邻的一个节点
-
缺点:
- 节点变化时会导致部分数据无法命中(指缓存数据,落点发生变化时缓存不命中,节点数越高,命中率越高)
- 节点数量较少时,节点变化影响范围较大,不适合少理数据节点的分布式方案
- 普通的一致性哈希分区,在增减节点时需要成倍/减半才能保证数据和负载均衡(只影响一个节点,对于其他几点就会出现负载倾斜的问题)
经常会通过采用虚拟节点(即,每台机都视为一组虚拟节点,同时加入 hash 环中)来增加节点间的复杂均衡,减少一致性哈希算法的缺点,而 redis 则采用虚拟槽的方式
3.2.1.3 哈希分区之虚拟槽分区
见章节[5.2.2 redis的虚拟槽分区](#5.2.2 redis的虚拟槽分区)
3.2.2 redis的虚拟槽分区
虚拟槽分区 通过使用 分散度良好 的 哈希函数(CRC16) 把所有数据 映射 到一个 固定范围 的 整数集合 中,该集合称为 槽(slot) 。
Redis Cluster槽范围为0 ~ 16383- 槽 是集群内 数据管理 和 迁移 的基本单位
- 落点计算为:
CRC16(key) % 16383 - 每个 Redis Cluster 的 master 管理一部分 slot,可以自动分配,也可以手动指定
3.2.2.1 Redis 虚拟槽分区的特点
- 解耦 数据 和 节点 之间的关系,简化了节点 扩容 和 收缩 难度。
- 节点自身 维护槽的 映射关系,不需要 客户端 或者 代理服务 维护 槽分区元数据。
- 支持 节点、槽、键 之间的 映射查询,用于 数据路由、在线伸缩 等场景。
3.2.2.2 Redis 虚拟槽分区的功能限制
功能限制:
key批量操作 支持有限:只支持在相同 solt 操作,如 mset, mget- 事物支持有限:只支持key在同一个节点上的事物操作
key为分区的最小粒度,一个大数据的key,不能被分配到不同的节点- 不支持多数据空间,只支持
db0 - 复制只支持一层:从节点 只能复制 主节点,不支持 嵌套树状复制 结构
3.2.2.3 Redis cluster 搭建
4. 布隆过滤
4.1 布隆过滤
布隆过滤: 用于判断数据是否不存在
- 对于不通过布隆过滤来讲,数据一定不存在
- 对于通过布隆过滤来讲,数据不一定存在
主要构成:
- 三个hash函数
- 一个bit数组
算法:
- 保存 key 时
- 用三个函数(f1,f2,f3)分别计算 key 的结果(r1,r2,r3)
- 把bit数组的,r1,r2,r3分别置为 1
- 查找 key 时
- 用三个函数(f1,f2,f3)分别计算 key 的结果(r1,r2,r3)
- 查找 bit 数组的第 r1,r2,r3 位是否都为 1
- 如果都为 1 则通过布隆过滤
- 如果有不为 1 则不通过布隆过滤
由于布隆过滤的特性,导致保存在布隆过滤中的数据越多,计算出的结果越容易命中,即使数据不存在布隆过滤中也会被命中,所以布隆过滤主要是保证过滤不命中的数据
- 通过增加 bit 数组的长度和使用不同的 hash 函数(空间增加),来降低布隆过滤的误命中
布隆过滤使用场景:
- 防止缓存穿透,大量的异常数据查找(不存在库中)频繁的缓存不命中,造成数据库压力过大
- 粗略判断一个元素在亿级数据中
- redis 缓存缓存穿透也是通用的到了,只有经过布隆过滤才能去查询缓存,不存在时穿透到数据库,而无法通过布隆过滤的直接返回为空
- 视频(文章)推荐列表,对于已经观看(阅读)过的视频(文章)优先级低于未观看(阅读):Now 直播发现页短视频瀑布流优化
4.2 拓展:布谷鸟过滤
5. redis 数据持久化
Redis 提供了 RDB 和 AOF 两种方式来实现数据的持久化存储
5.1 RDB
- RDB 操作的两种机制:
- save :save 命令会阻塞当前 Redis 服务,直到 RDB 备份过程完成,在这个时间内,客户端的所有查询都会被阻塞;
- bgsave :Redis 进程会 fork 出一个子进程,阻塞只会发生在 fork 阶段,之后持久化的操作则由子进程来完成。
- RDB 可以手动执行两种机制
- RDB 自动触发:
- 在
redis.conf中配置了save m n,表示如果在 m 秒内存在了 n 次修改操作时,则自动触发bgsave; - 如果从节点执行全量复制操作,则主节点自动执行
bgsave,并将生成的 RDB 文件发送给从节点; - 执行
debug reload命令重新加载 Redis 时,会触发save操作; - 执行
shutdown命令时候,如果没有启用 AOF 持久化则默认采用bgsave进行持久化。
- 在
- 相关配置:
- 修改持久化文件(默认为 Redis 的工作目录下 dump.rdb)
redis.conf中的工作目录dir和数据库存储文件名dbfilename两个配置- 动态修改:通过在命令行中执行命令:
config set dir{newDir} config,set dbfilename{newFileName}
- 修改压缩算法( 默认采用 LZF 算法)
redis.conf中的rdbcompression配置config set rdbcompression{yes|no}命令
- 修改持久化文件(默认为 Redis 的工作目录下 dump.rdb)
5.2 AOF
以独立日志的方式记录每次写入操作,重启时再重新执行这些操作,从而达到恢复数据的命令
- 同步策略
appendfsync- always :命令写入 aof_buf 后就调系统 fsync 操作同步到 AOF 文件
- everysec :命令写入 aof_buf 后就调用系统的 write 操作,但 fsync 同步文件的操作则由专门线程每秒调用一次
- no :命令写入 aof_buf 后就调用系统的 write 操作,不对 AOF 文件做 fsync 同步,同步操作由操作系统负责,通常同步周期最长为30秒
- 相关配置:
- 想要使用 AOF 功能,需要配置
appendonly的值为yes,默认值为no。 - 默认 AOF 的文件名为
appendonly.aof, 可以通过修改appendfilename的值进行修改,和 RDB 文件的保存位置一样,默认保存在 Redis 的工作目录下
- 想要使用 AOF 功能,需要配置
5.3 RDB & AOF
RDB 优缺点
-
优点:
- 一次性生成快照,结构紧凑,适用于备份和全量复制等场景
- 持久化文件小,恢复速度快
- 由子线程执行磁盘 I/O 操作,性能高
-
缺点:
-
实时性低,在持久化间隔间会宕机会出现数据丢失
-
fork 操作是重量级操作,数据大时, fork 操作非常耗时
-
AOF 优缺点
- 优点:
- 实时性搞,确保数据的最少丢失
- 缺点:
- 生成持久化文件大
- 根据选择的同步策略的不同,AOF 可能比 RDB 还慢。
按照 Redis 官方的推荐,为保证的数据安全性,可以同时使用这两种持久化机制,在 Redis 官方的长期计划里面,未来可能会将 AOF 和 RDB 统一为单一持久化模型。
需要注意的是,当 Redis 重新启动时,Redis 将使用 AOF 文件重建数据集,因为它可以保证数据的最少丢失。
本文作者:Yui_HTT
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!