目录
串(string)是由零个或多个字符组成的有限序列,又名叫字符串。
1. 定义
- 串(string)是由零个或多个字符组成的有限序列,又名叫字符串。
- 0 个字符的串称之为空串(null String)
- 概念
- 空格串:只包含空格,有内容有长度,不同于空串
- 子串与主串:串中任意个数的连续字符组成的子序列称为该串的子串,相应地,包含子串的串称为主串。
- 子串在主串中的位置就是子串的第一个字符在主串中的序号。
2. 串的抽象数据类型
cADT串(string)
Data串中元素仅由一个字符组成,相邻元素具有前驱和后继关系。
Operation StrAssign(T,*chars):生成一个其值等于字符串常量chars的串T。
StrCopy(T,S):串S存在,由率s复制得串T。
ClearString(s):串S存在,将串清空。
StringEmpty(s):若率s为空,返回true,否则返回false。
StrLength(s):返回串S的元素个数,即串的长度。
StrCompare(s,T):若s>T,返回值>0,若S=T,返回0,若S<T,返回值<0。
Concat(T,S1,S2):用T返回由S1和S2联接而成的新串。
subString(sub,S,pos,1en):串S存在,1≤pos≤StrLength(s),且0≤len≤StrLength(s)-pos+1,用Sub返回串S的第pos个字符起长度为1en的子串。
Index(s,T,pos):串S和T存在,T是非空率,1≤pos≤StrLength(s)。
若主串S中存在和串T值相同的子事,则返回它在主串S中第pos个字符之后第一次出现的位置,否则返回0。
Replace(S,T,V):率S、T和V存在,T是非空率。用V替换主串S中出现的所有与T相等的不重叠的子串。
StrInsert(s,pos,T):串S和T存在,1≤pos≤StrLength(s)+1。
在串S的第pos个字符之前插入串T。
StrDelete(s,pos,1en):率s存在,1≤possStrLength(s)-1en+1。从串S中删除第pos个字符起长度为1en的子串。
endADT
3. 串的存储结构
3.1 顺序存储(定长数组存储)
串的顺序存储结构是用一组地址连续的存储单元来存储串中的字符序列的。按照预定义的大小,为每个定义的串变量分配一个固定长度的存储区。一般是用定长数组来定义。
- 字符串长度
- 有的语言会在下标为0的地方保存串的长度
- 有的语言会在最后一个下标的地方保存串的长度
- 有的语音不保存串的长度,而在结尾添加一个"\0" 来表示结束,需要获取长度时去遍历计算
- 对于定长的数组存储的弊端
- 定长的数组,至多只能输入固定长度的字符
3.2 链式存储
链式存储的话,每个节点要放多少个字符是一个问题。而且无论是从性能还是操作的方便性都不如顺序存储= =
4. 朴素的模式匹配算法
5. KMP 模式匹配算法
初略讲解,会在算法动态规划中详讲
5.1 KMP 模式匹配算法原理
5.1.1 例一
主串 S="abcdefgab"
子串 T="abcdex"
朴素的模式

KMP 模式匹配算法与朴素的模式匹配算法不一样在于图的 ② 到 ⑤,对于匹配模式来讲依次遍历是必须的,而 KMP 算法,在判断到子串 T 的首字母 a, 与后面 bcdex 都不一样(这是前提),而在第一次匹配时 bcde 都匹配上了,只有 x 没有匹配到,那下一次,会从 ⑥ 处开始匹配
5.1.2 例二
主串 S="abcabcabc"
子串 T="abcabx"
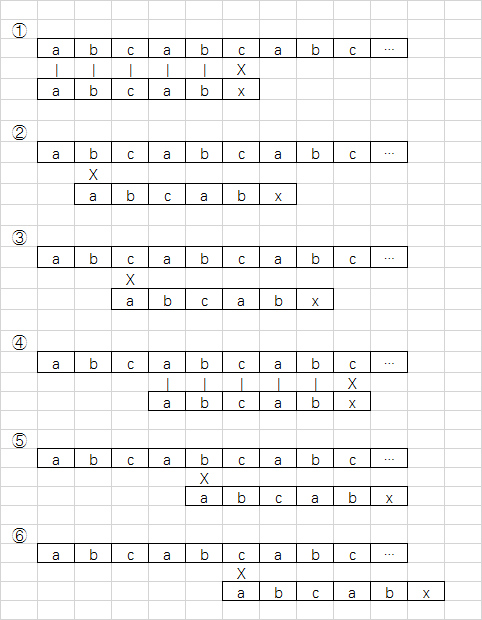
- 前五个字符完全相等,第六个字符不等,如①所示
- T 的首字母 "a" 与 第二,第三字符均不等,所以省略 ②③
- 因为 T 的首位与 T 的第四位相等,第二位与第五位相等。而在 ① 时,T 的第四,第五位均与主串 S 中的相应位置比较过了,所以 T 的首位和第二位字符与 S 的第四,第五位肯定是匹配的,不需要再匹配,所以第 ④⑤步骤是可以省略的
5.2 KMP
5.2.1 匹配值表(next[])
前缀:从 0 位,依次截取 1 到(len - 1)长度字符串的集合 后缀:从 len - 1 位反序,依次截取 1 到(len - 1)长度字符串的集合
以子串 T="ABABABCA" 为例
| 字符串 | 前缀集合 | 后缀集合 | 前缀后缀交集 |
|---|---|---|---|
| "A" | [] | [] | [] |
| "AB" | [A] | [B] | [] |
| "ABA" | [A,AB] | [A,BA] | [A] |
| "ABAB" | [A,AB,ABA] | [B,AB,BAB] | [AB] |
| "ABABA" | [A,AB,ABA,ABAB] | [A,BA,ABA,BABA] | [A,ABA] |
| "ABABAB" | [A,AB,ABA,ABAB,ABABA] | [B,AB,BAB,ABAB,BABAB] | [AB,ABAB] |
| "ABABABC" | [A,AB,ABA,ABAB,ABABA,ABABAB] | [C,BC,ABC,BABC,ABABC,BABAC] | [] |
| "ABABABCA" | [A,AB,ABA,ABAB,ABABA,ABABAB,ABABABC] | [A,CA,BCA,ABCA,BABCA,ABABCA,BABABCA] | [A] |
“匹配值”是指前缀和后缀集合,最长共有元素的长度,即交集中最长元素的长度
所以匹配值表为
| -- | -- | -- | -- | -- | -- | -- | -- | -- |
|---|---|---|---|---|---|---|---|---|
| char | A | B | A | B | A | B | C | A |
| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| value | 0 | 0 | 1 | 2 | 3 | 4 | 0 | 1 |
5.2.2 匹配值表使用
移动位数 = 已匹配字符长度 - 对应位的匹配值
举例:
主串 S="BACBABABAABCBABABABCA"
子串 T="ABABABCA"
设主串匹配游标为 i, 子串游标为 j
第1次匹配成功: BACBABABAABCBABABABCA | ABABABCA 此时 i = 1, j = 0;已匹配字符长度为=1 移动长度为 1 - 0 = 1 ---------------------------------------- 第2次匹配成功: BACBABABAABCBABABABCA ||||| ABABABCA 此时 i = 8, j = 4;已匹配字符长度为=5 移动长度为:5 - next[j=4] = 5-3 = 2; BACBABABAABCBABABABCA XX||| ABABABCA 此时 i = 8, j = 2;已匹配字符长度为=3 移动长度为:3 - next[j=2] = 3-1 = 2; BACBABABAABCBABABABCA XXxx| ABABABCA 此时 i = 8, j = 0;已匹配字符长度为=1 移动长度为:1 - next[j=0] = 1-0 = 1;
本文作者:Yui_HTT
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录